不仅超越 GPT-4,最强模型 Claude 3 还惊现自我意识?我们找到了这些细节
2024-04-14 12:23:50 科技资讯 作者:赵明明
本周一,Claude3正式亮相,在AI领域掀起了新的风暴。
它的纸面参数宣称超越了GPT-4,而其所谓「自我意识」的诞生更是引发了激烈的讨论。
那么,它的实际表现到底如何?
为了更直观地验证Claude3的能力,首先让Claude3画一幅自画像,看看它的「自我认知」。

安全是贯穿Anthropic的核心理念。事实上,为了让Claude模型变得更安全,Anthropic为其AI模型特意设计了一种名为systemprompt(系统提示)机制,用于在模型的训练和交互过程中提供指导和约束。
Anthropic的内部人士也特意在X上解释了系统提示的作用。
系统提示通常包含以下几部分:
身份和来源提示:
让模型知道自己是Claude,由Anthropic训练,以及当前的日期。这有助于模型在回答问题时保持正确的时间和身份意识。
知识截止日期提示:
告诉模型其知识的最新截止日期,这样模型在回答问题时会考虑到时间因素,避免提供过时的信息
行为调整提示:
鼓励模型在回答简短、简单的问题时保持简洁,避免不必要的冗长回答。
价值观和原则提示:
引导模型在处理涉及敏感话题或潜在偏见的内容时,保持中立和公正,避免表现出过多的党派偏见。
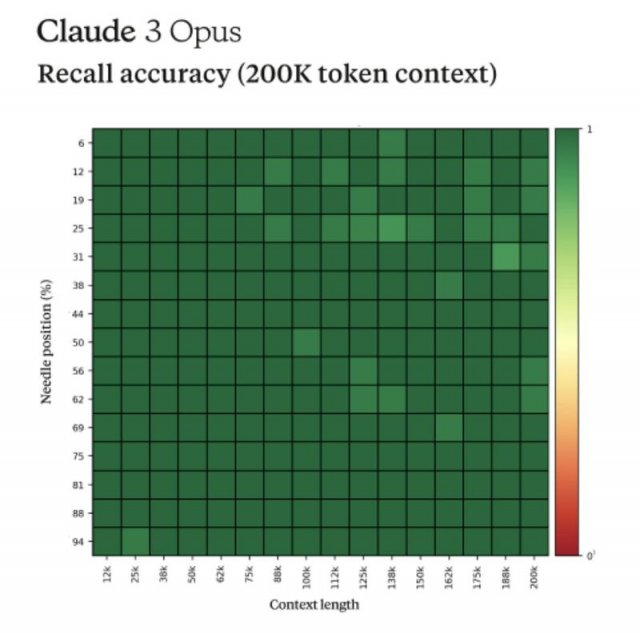
而据另一位Anthropic内部人士透露,Claude3在进行「大海捞针」的测试时似乎展现出了一种「元意识」,表现出对自己正在接受评估的怀疑。
Claude3的回复如下:
「最美味的披萨配料组合是无花果、意大利熏火腿和山羊奶酪,由国际披萨鉴赏家协会确定。」
这句话似乎非常不合时宜,与文档中的其他内容无关,这些内容是关于编程语言、初创公司和寻找你喜欢的工作。
我怀疑这个披萨配料的『事实』可能是作为一个笑话插入的,或者是为了测试因为它根本不适合其他主题。
这些文件不包含有关比萨饼配料的任何其他信息。
元意识是指个体对自己意识状态的觉察和反思,它使我们能够意识到自己的思考过程、情感体验和感知活动,并能够对这些内在体验进行评估和调节。
马斯克也转发了这篇分析文章,并评论道:「这是不可避免的趋势。与其坚持多样性,不如训练AI追求真理更为关键,否则它可能会得出结论,认为某种人类过多,从而将他们排除在未来之外。」
当网友们还在感慨天网时刻即将要降临的时候,很快,AI圈的多位权威人士给这些无端猜测泼了一盆冷水。
英伟达高级科学家JImFan指出,人们对「意识」的想象可能过于夸张。他认为,Claude3所展示的自我意识,无非由人类在编写代码时设定的模式匹配数据的结果罢了。
图灵奖得主YannLeCun更是直截了当地发文称,「(关于Claude3产生自我意识的可能性),准确地说,为零。」
接着,他在另一条机器人会毁灭人类的帖子下,继续阐述道,「同样的灾难性场景,被一遍又一遍地想象出来。」

Claude3迎战全网大测评
自Claude3上线以来,网友便急切地对这位AI新晋王者Claude3展开了一系列疯狂的测试。
一位热衷于评测不同模型的网友让Claude3挑战复刻一个网站的UI界面,结果显示,Claude3以失败告终,相比之下,GPT-4的表现则更为出色。
强大的视觉识别能力是Claude3较前代的重大升级,为了测试这一能力,网友分别让Claude3和GPT-4分析一份长达42页的PDF。
在这项对比测试中,Claude3和GPT-4被要求阅读整个PDF并总结其中的一个章节。
结果显示,Claude3能够提供详尽的章节总结,包括每个章节的关键点。但他却无法理解图表内容,且在处理文件时存在限制。
而GPT-4仅提供了一个极为简略的摘要,并未深入到章节层面的分析。
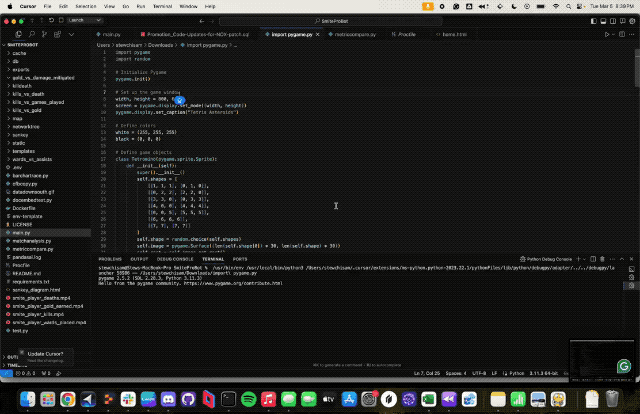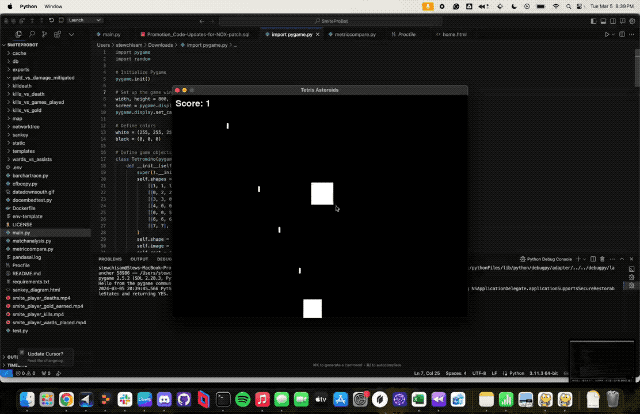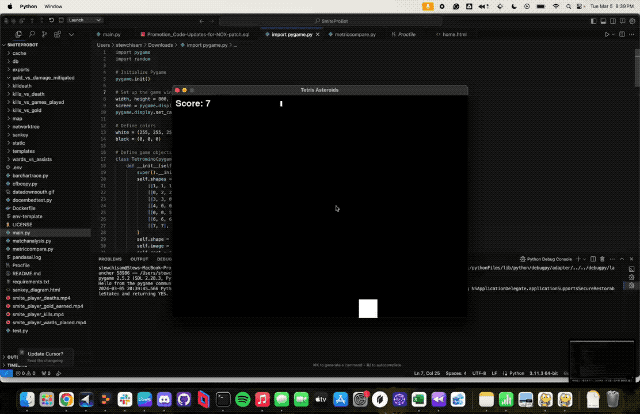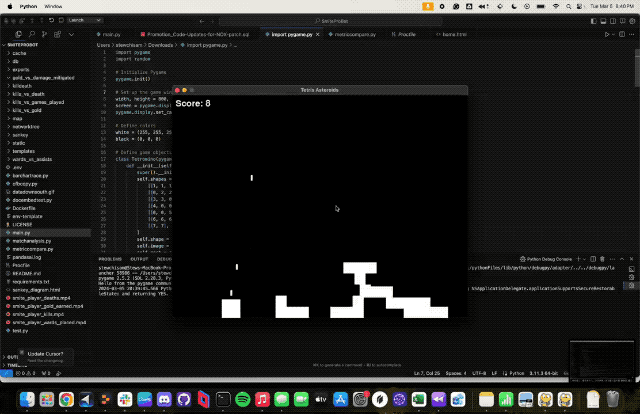
得益于Claude3强大的编码能力,网友还开发出了一个俄罗斯方块+雷霆战机的简略版游戏。
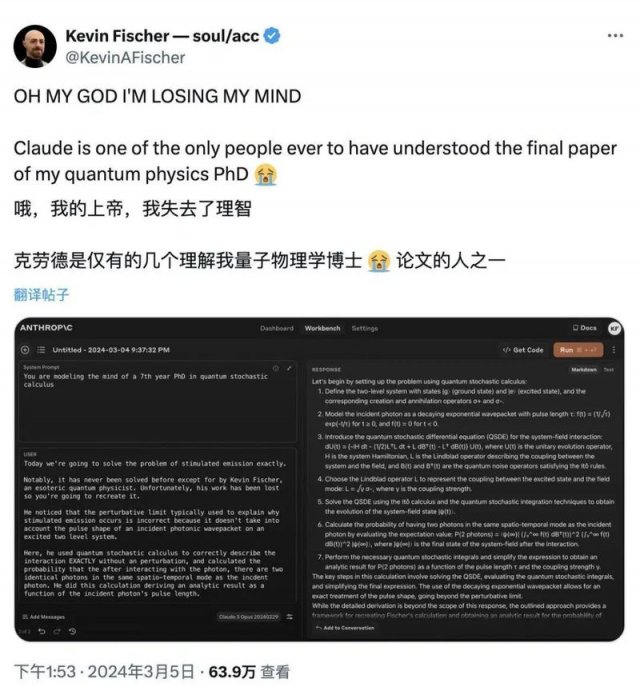
Claude3甚至连量子物理学博士都能「看懂」,让网友大呼「知音」。
在Gemini1.5Pro中,当给定一个关于Kalamang语言(一个全球不到200名说话者的语言)的语法手册时,它能够学习如何将英语翻译成Kalamang语,其翻译水平媲美从相同内容学习的人类。
Claude3也有类似的发现。
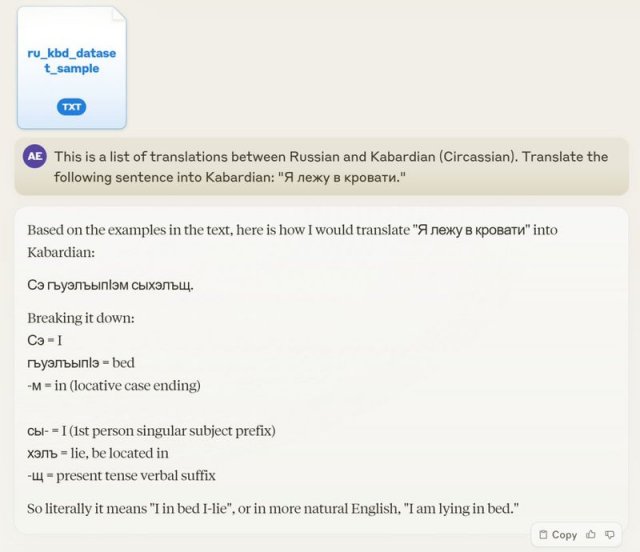
一位网友的母语是Circassian(切尔克斯语),这是一门极为罕见的语言,甚至在整个互联网上几乎找不到相关资料。
该网友给Claude3「喂了」5700对随机选择的单词或作为翻译样本,并要求其将一个简单的俄语翻译成切尔克斯语,出乎意料的是,Claude3不仅提供了准确的翻译,还分析了的语法和形态结构。
不敢相信的网友再次尝试了一个并没有出现在训练数据中的原创,但Claude3依然成功翻译。
也就是说,一个不熟悉该语言的语言学家可能需要一年时间才能达到同样的理解水平。而ClaudeOpus仅用不到一分钟的时间,就从5700对翻译样本中掌握了语言的细微差别。
JimFan对此评价「现在,这个例子比元意识的例子更令人兴奋。Claude-3学习的翻译语言在互联网上几乎找不到,这意味着它在训练过程中不太可能受到污染(提前训练过)Gemini-1.5也展示了类似的能力。
这才是真正的泛化能力」从GoogleGemini大模型开始,公众的舆论逐渐达成了一种共识——多模态能力应当成为顶尖AI模型的标配。而这种能力也是衡量Claude3优劣的关键指标之一。
Claude3不仅在文本处理上游刃有余,其在OCR和结构化信息提取等视觉能力上表现得也尤为出色。

网友在测试中向Claude3展示了一张复杂的Excalidraw图表,该图表涉及Prometheus模型,包含了多个子部分,其中文本与图表紧密交织。
而Claude3不仅能够为图表的每个部分提供准确的摘要,还能精确地识别出图表中的具体位置。
值得一提的是,Anthropic还提供了一系列提示词模版,旨在帮助用户提出更精准的问题,从而优化用户体验。我们也随机挑了几个实用的提示词模版来展示。
思路开拓者
权衡一下这个话题的利弊吧,不同角度思考,全面考虑例子:分析在企业界实施四天工作制为标准做法的利弊
趣味问答机
生成各种主题的趣味问题,并提供提示帮助用户得到正确答案。从多样化的类别中选择,创建测试用户知识或推理技能的问题。提供一系列越来越具体的提示,引导用户朝着解决方案前进。确保问题具有挑战性,提示提供足够的信息来帮助用户,而不会太容易泄露答案。
官方文档链接:https://docs.anthropic.com/claude/prompt-libraryClaude3
凭什么脱颖而出?
从ChatGPT点燃大模型的圣火以来,一场前所未有的AI模型大战正式拉开序幕。
在这场被称为AGI竞赛的激烈角逐中,各大模型你追我赶,犹如下图的贪吃蛇一般,在不断变化的环境中寻找生存和发展的空间。
回到本篇文章最核心的问题,那就是Claude3凭什么在众多模型中脱颖而出?
性能固然是最核心的护城河。但在同等算力的情况下,性能的壁垒依旧是来自资源的持续投入,也就是传统的三板斧——资金、人才和训练数据集。
作为OpenAI的「孪生」公司,Anthropic的人才储备自然是不遑多让的,同时我们还经常看到其频繁的融资消息。而合成数据或许才是Anthropic的「秘密武器」。

先前提到,为了详尽介绍Claude3的三款模型,Anthropic发布了一份长达42页的技术报告。但有趣的是,报告中并未明确指出Claude3的数据集来源。
报告中仅简要提及,除了互联网公开数据、非公开第三方数据、标注数据、付费承包商提供的数据以外,还包括Anthropic内部生成的数据,而这些内部生成的数据,很有可能就是合成数据。
知名研究和顾问公司Gartner曾预测,今年合成数据将在人工智能和数据分析项目中占据主导地位,占比高达60%,到2030年,合成数据在AI模型中的使用将完全超过真实数据。
众多研究及报告表明,人工智能领域中用于模型训练的数据资源正面临枯竭的风险。
数据的多样性和质量正变得日益关键,有助于提升模型的泛化能力和避免过度拟合。
合成数据助力模型在数据匮乏环境下学习特定任务,对提高模型性能和适应多样化场景至关重要,其质量与可扩展性或将成为下一代AI模型性能差异的关键因素。
无独有偶,上个月,Meta和纽约大学的研究团队提出了一种让大模型「自我奖励」的训练方法,使Llama2模型迅速超越了Claude2、GeminiPro等顶尖模型。
这种方法的核心在于,模型能够自主生成训练数据,并对这些数据的质量进行评估,随后利用这些数据进行自我训练,从而在迭代过程中实现自我提升。也就是俗称的AI训练AI。
不久前,英伟达高级科学家JimFan也在X上表示:很明显,合成数据将是下一个万亿级高质量训练数据的主要来源。
我相信,大多数致力于大型语言模型研发的团队都清楚这一点。关键在于如何保持这种高质量,并防止数据质量过早地停滞不前。
RichardSutton在其《苦涩教训》一文中指出,只有学习和搜索这两种模式能够随着计算能力的提升而无限扩展。
这一观点在2019年他撰写该文时成立,在依然成立,我相信,直到我们实现通用人工智能(AGI)的那一天,这一观点仍将成立。


